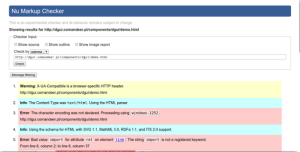
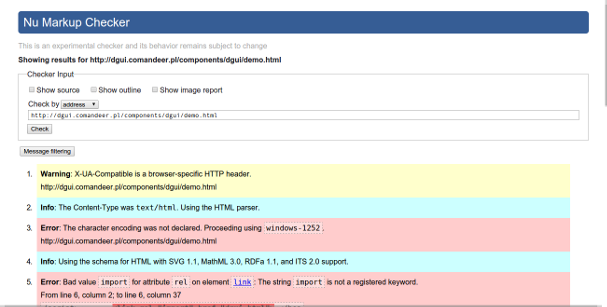
Walidator w działaniu
Swego czasu najwyższym zaszczytem dla każdego webmastera był znaczek (X)HTML valid, dowodzący niepodważalnej znajomości wszelkiego rodzaju dziwactw zawartych w specyfikacji czy też zapamiętania długiej listy zdeprecjonowanych elementów/atrybutów. Ale czasy się zmieniły…
DTD – Deprecated Tool of Doom
Czy ktoś jeszcze pamięta stare, dobre
DOCTYPE dla HTML 4 lub – o zgrozo! – dla XHTML 1.0?
|
|
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd"> |
Przerażające i nic niemówiące rzędy literek, których jedynym celem było… zapewnianie zgodności z wszechwiedzącym walidatorem. Tak naprawdę ta linijka nie robiła nic oprócz tego (ok, był jeszcze tryb quirks, ale to już w ogóle stare dzieje…) i do dzisiaj nie robi. Nic zatem dziwnego, że HTML 5 pozbywa się tej głupoty całkowicie i zostawia nas z prostym:
Ale jak to – jakim cudem taki króciutki zapis może zastąpić tak rozwlekłą deklarację, w której jest nawet element oznaczający zgodność ze standardem ISO (tak, jest takowy!)? Otóż bardzo prosto – żadna przeglądarka nigdy nie używała DTD… Zgodnie ze specyfikacją HTML 4, powstałą w czasach SGML-a i rodzącego się boomu na XML, parsowanie HTML-a powinno przebiegać następująco:
- poszukujemy
DOCTYPE
- jeśli go nie ma, uruchamiamy tryb quirks (aka tryb IE5)
- jeśli jest, szukamy adresu do pliku DTD
- pobieramy plik DTD
- parsujemy plik zgodnie z zasadami DTD
- cieszymy się sparsowaną stroną (albo i nie)
Niby proste i logiczne, prawda? Ale punkt 4. powinien każdemu webdevowi dać do myślenia – wszak to pewny DDOS. Miliony przeglądarek na świecie ślące w tej samej sekundzie zapytania na nasz serwer tylko po to, żeby dowiedzieć się jak sparsować stronę… Przerażające i całkowicie niepraktyczne. Tak bardzo niepraktyczne, że żadna przeglądarka nigdy nie pobiera żadnego DTD. Ba, nigdy nawet nie parsuje według zasad narzuconych przez ten plik. Po prostu przeglądarka ma sobie zapisanych kilka zasad, według których wszystko działa i tyle.
Co więcej, każda przeglądarka robi wszystko, żeby wyświetlić nawet te strony, które ewidentnie łamią wszelkie logiczne zasady konstrukcji poprawnego kodu. Problemem większym od niezgodności stron z objawioną prawdą DTD okazał się zatem… brak standaryzacji mechanizmu poprawiania błędów na stronach w przeglądarkach, który to specyfikacja HTML 5 naprawia. Tym samym ostatnie pozostałości po pradawnych DTD zniknęły, ustępując miejsca sensownym mechanizmom, takim jak RelaxNG. No prawie zniknęły…
Nie-walidator
Jedynym miejscem, w którym DTD jest wciąż faktycznie używane to walidator W3C. Prastara świątynia stron zgodnych ze standardami pozostała niewzruszona na dobrą nowinę HTML 5 i wciąż próbuje wszystkim wmówić, że reguły zapisane w DTD są tym, czego oczekujemy od Sieci. Czy aby na pewno?
Na szczęście niedoskonałość tej techniki została zauważona i powstał lepszy walidator, szybko zaadaptowany przez W3C, który nie jest walidatorem.
It’s an automated thing which checks stuff for you that’d otherwise be really tedious for you to check manually. So it helps you. Maybe it should be called the Nu Help-You Checker.„http://html5doctor.com/html5-check-it-before-you-wreck-it-with-miketm-smith/”
Tak, najnowszy walidator nie jest walidatorem, ale sprawdzaczem zgodności ze specyfikacją. Oznacza to mniej więcej tyle, że to, co specyfikacja uznała za błąd, walidator też za takowy uzna. Tylko tyle i aż tyle.
Nie-walidator, a rzeczywistość
Pomyślmy nad sensownymi powodami wymuszania pełnej zgodności strony ze specyfikacją:
- chcemy sprawdzić czy przypadkiem nie zamknęliśmy jakichś znaczników źle lub nie zrobiliśmy literówki w nazwie atrybutu
- potrzebujemy zgodności z normą WCAG 2.0 (choć to tak nie do końca, bo ta norma wymusza jedynie syntaktyczną poprawność)
- ktoś nam kazał zrobić dokument zgodny ze specyfikacją
- chcemy być fajni
Więcej sensownych powodów wymyślić nie potrafię. Dwa pierwsze są ze sobą ściśle zespolone i jeśli używam do czegoś nie-walidatora, to właśnie do sprawdzania poprawności syntaktycznej. Dwa kolejne… cóż, szefa zawsze można zmienić, a fajność naprawdę nie zależy od żółtego znaczka walidatora (serio!).
Obecnie, przy istnieniu żywej specyfikacji HTML, nie-walidator musi być nieustannie uzupełniany, co i tak nie rozwiązuje problemu. A co z np. Web Components, które z założenia nie będą występować w specyfikacji? Co z niestandardowymi atrybutami (które obecnie mogą być zgodne ze specyfikacją, przy wykorzystaniu tzw. datasetów)? Co z targetowaniem specyficznych platform? Co z ARIA w HTML 4? Takie przykłady można mnożyć.
Obecny nie-walidator i tak jest domyślnie zbyt upierdliwy, czepiając się wszystkich nieznanych sobie atrybutów i elementów, co sprawia, że w przypadku wspomnianych już Web Components jest po prostu nieużywalny. Na szczęście pozwala filtrować rzucane przez siebie błędy i wybrać jedynie te, które naprawdę nas interesują.
Ale i tak to nie jest wystarczające… Bo obecnie inicjalny HTML często nie ma nic wspólnego z generowanym drzewkiem DOM strony, nie wspominając już o Shadow DOM, który ma całkowicie odrębne zasady parsowania! Jak sprawdzać poprawność tych elementów? I czy w ogóle ma to jakikolwiek sens?
Precz z walidacją!
Walidacja musi odejść! Jej czas się już skończył – DTD umarło, a wraz z nim ścisłe ograniczenia parsowania HTML-a i innych pochodnych SGML-a. Te zasady i tak zawsze były tylko teoretyczne.
Sprawdzanie zgodności ze specyfikacją ma zastosowanie tylko dla dokumentów, które z założenia mają być z nią zgodne, co dotyczy większości stron internetowych w Sieci, lecz niekoniecznie aplikacji (internetowych i nie tylko). Co więcej – zgodność ze specyfikacją HTML 5 nie oznacza zgodności ze specyfikacją HTML 4 (inna rzecz, że nie ma żadnego sensownego powodu, żeby wciąż HTML 4 używać), więc w zależności od
DOCTYPE możemy otrzymać całkowicie różne wyniki.
Nowy walidator powinien rozumieć składnię HTML 5 i rozpoznawać elementy poprawne syntaktyczne i, jeśli taka jest nasza wola, oznaczać elementy nie występujące w specyfikacji HTML 5. Nie powinien jednak wymuszać na nas czegoś, czego nie potrzebujemy (inna rzecz, że jeśli HTML 5 na coś pozwala, a my i tak robimy świadomie niezgodnie ze specyfikacją, to nie ma to zbytniego sensu – patrz: customowe atrybuty mimo istnienia datasetów).
Czego potrzebujemy? Tego, co obecnie ma JS pod postacią ESLinta: modularnego systemu sprawdzania poprawności stron, który nie dość, że będzie sprawdzał to, co rzeczywiście jest nam potrzebne, ale będzie umiał sobie radzić z dynamicznymi stronami. Nie ukrywam, że czymś fantastycznym byłaby modularna wersja Kwality (który to niestety zdechł pewien czas temu) i prawdę mówiąc pracuję nad takim narzędziem.
Przestańmy być w końcu niewolnikami walidacji i zacznijmy ją traktować jak normalne narzędzie, od którego nasz rozum developera jest zawsze ważniejszy.
Warto poczytać:
Tagi: W3C • walidacja




Marta
Świetnie pokazane, jak jedno małe ustawienie może realnie poprawić UX na mobile'u – szczególnie przy dłuższych formularzach, gdzie każdy klik ma znaczenie. Ciekawi mnie, czy przeglądarki mobilne zawsze konsekwentnie interpretują inputmode, czy są tu jakieś różnice między Androidem a iOS-em?2025-07-21 16:43:00