Słyszałem gdzieś kiedyś opinię, w której to blokowanie nagłówków tabeli z poziomu CSS działa tylko i wyłącznie w demach artykułów, w których się znajdują. Postaram się dzisiaj zagiąć czasoprzestrzeń tak, by końcowy efekt wyszedł z tej czarnej dziury przez horyzont zdarzeń i zadziałał również u Ciebie (oczywiście jeśli mówimy o najnowszych przeglądarkach).
Przygotowanie szkieletu tabeli
Tabela testowa będzie posiadała kilka kolumn i wiele wierszy, aby ukazać blokadę nagłówków w działaniu. Treścią się nie przejmujemy, dodając Lorem Ipsum.
Jeśli jesteś zainteresowany efektem końcowym, zerknij na poniższe GIFy lub odwiedź stronę: https://webroad.pl/demo/table-sticky-headers/
Nie chciałem rozciągać listingu w nieskończoność – powiel więc poniższą część
<tbody> i zawarte w niej wiersze kilkadziesiąt razy, tak by pojawił się suwak pionowy.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
<table> <thead> <tr> <th>Lorem</th> <th>Ipsum</th> <th>Dolor</th> <th>Sit</th> <th>Amet</th> <th>Lorem</th> <th>Ipsum</th> <th>Dolor</th> <th>Sit</th> <th>Amet</th> </tr> </thead> <tbody> <tr> <th scope="row">Consectetur adipiscing elit</th> <td>Nunc libero purus, venenatis hendrerit feugiat</td> <td>Fusce et leo tristique, sollicitudin leo ut, mattis augue</td> <td>Praesent placerat, libero sit amet suscipit</td> <td>Cras laoreet dolor vitae velit sollicitudin</td> <td>Consectetur adipiscing elit</td> <td>Nunc libero purus, venenatis hendrerit feugiat</td> <td>Fusce et leo tristique, sollicitudin leo ut, mattis augue</td> <td>Praesent placerat, libero sit amet suscipit</td> <td>Cras laoreet dolor vitae velit sollicitudin</td> </tr> </tbody> </table> |
Style tabeli, aby nie wyglądała zbyt surowo, niech będą następujące:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
table { color: #333; background: white; border: 1px solid #888; font-size: 12pt; border-collapse: separate; border-spacing: 0; border-radius: 3px; font-family: Arial, Helvetica, sans-serif; } table th, table td { padding: 1rem; border: 1px solid #888; text-align: left; white-space: nowrap; color: #777; } table th { background-color: #888; color: #fff; } |
Efekt na ten moment:
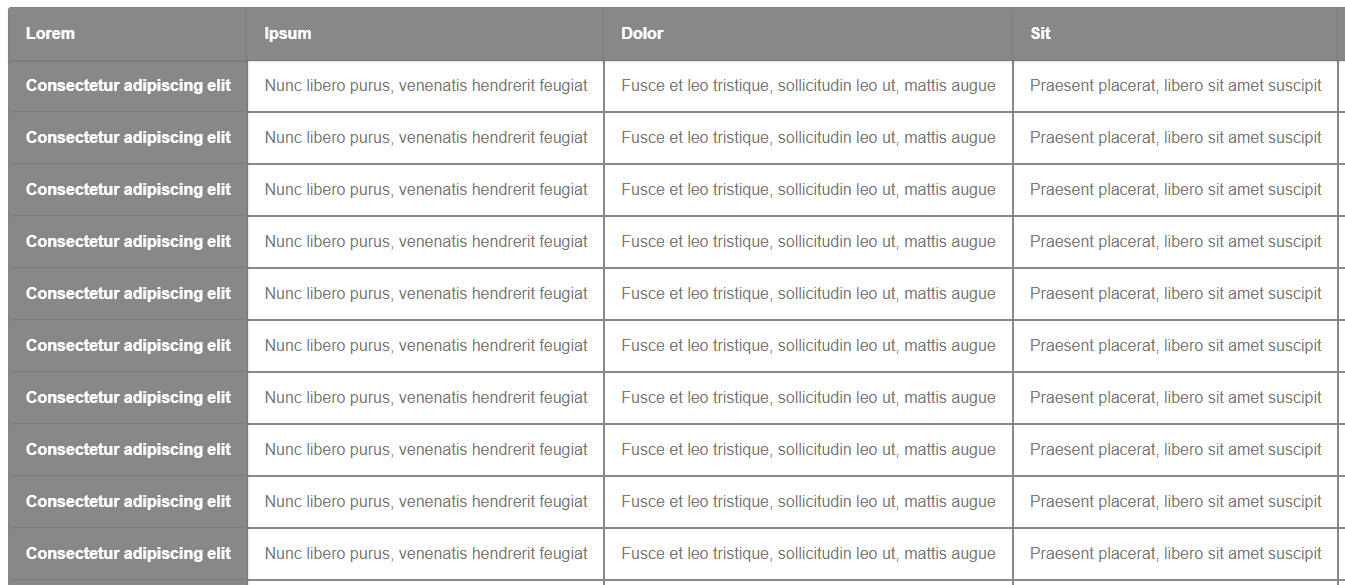
Tabela z nagłówkami
Czas na część właściwą. Blokujemy nagłówki.
Blokowanie nagłówków przy przewijaniu strony w pionie
Najczęściej potrzebujemy właśnie tej blokady – górny wiersz nagłówka ma zostać przyklejony do górnej części ekranu. By uzyskać ten efekt w dokumencie HTML wystarczy dopisać do powyższej tabeli następujące kilka linijek kodu CSS:
|
|
table thead th { position: sticky; top: 0; z-index: 10; box-shadow: 0 1px 3px rgba(0, 0, 0, 0.2); } |
Po odświeżeniu widoku i przewinięciu pionowym suwakiem nagłówek pozostanie na górze.

Zablokowany nagłówek poziomy tabeli
Blokowanie nagłówków przy przewijaniu strony w poziomie
Blokowanie pierwszej kolumny nie jest zbyt popularne, jednak często klient przyzwyczajony do blokad kolumn w Excelu może sobie zażyczyć i taką funkcjonalność.
Jeśli wcześniej nie zauważyłeś, spójrz ponownie na listing HTML tabeli, szczególnie na pierwszą kolumnę wiersza.
|
|
<tr> <th scope="row">Consectetur adipiscing elit</th> <!-- Pozostałe kolumny --> </tr> |
Zamiast
<td> użyliśmy komórki
<th> z atrybutem
scope o wartości
row. Mając tak przygotowaną kolumnę możemy teraz dodać odpowiednie style, aby ją zablokować.
|
|
table tbody th[scope=row] { position: sticky; left: 0; z-index: 9; box-shadow: 1px 0 3px rgba(0, 0, 0, 0.2); } |
Co otrzymaliśmy?

Zablokowany pionowy nagłówek tabeli
Super! Czy u Ciebie działa? :-)
Na co zwrócić uwagę przy blokowaniu nagłówków?
Kilka wskazówek do wdrażania blokady nagłówków zebrałem i wypisałem na poniższej liście:
- dodajemy
z-index większy dla komórek w nagłówku poziomym, aby nagłówek pionowy chował się pod spód,
- jeśli blokujemy nagłówek przy przewijaniu pionowym określamy pozycję
top lub
bottom,
- jeśli blokujemy nagłówek przy przewijaniu poziomym określamy pozycję
left lub
right,
- dodajemy kolor tła do nagłówków, aby komórki przesuwane nie były widoczne przy przewijaniu po nimi,
- dodajemy cień, aby ukazać warstwy nadrzędne, jakimi są nagłówki.
Kod i demo
Kod z powyższego przykładu zamieściłem na GitHubie.
Demo możesz zobaczyć na specjalnie przygotowanej stronie.
Tagi: css • HTML • nagłówek • sticky • tabela




